
How We Moved Our Data Center 25 Miles Without Downtime
Cross-posted at How We Moved Our Data Center 25 Miles Without Downtime.
We recently migrated to a new data center at Braintree. This move was completed without losing a single transaction, emphasising uptime and high availability. We’ll focus on our approach to high availability, our current infrastructure, the detailed steps of the migration and the next steps we’re taking with our infrastructure.
High Availability
Braintree’s business is processing credit cards for merchants. This means when we’re down, our merchants can’t accept payments online. Uptime is a core feature of our business, and we do everything we can to make sure we are always up.
One of the ways that we are going to ensure uptime in the future is by switching to an active-active setup. This means we will have multiple, active data centers at all times. When one data center has a problem, we can unbalance the whole data center and send traffic only to the other data center.
The first step in this plan was to switch our main traffic to a new data center with a new set of networking equipment and a BGP multi-homed block of IP addresses. We decided to set up a new data center rather than migrate our current data center to isolate the changes from our existing production environment.
Once we had a new data center ready, it was time to switch over to it.
Our infrastructure
Before we detail the steps of the move, we need to describe the core of our current infrastructure setup.
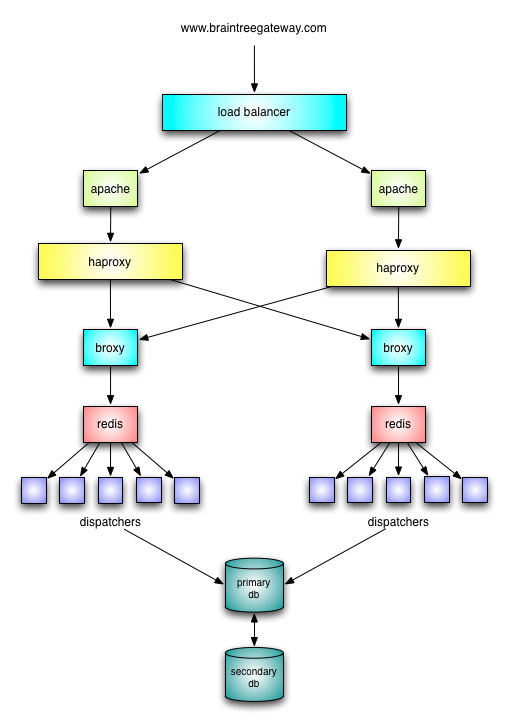
Traffic flows in through networking equipment to multiple apache instances, which serve static assets, handle SSL, and then proxy the remaining traffic to haproxy. Haproxy balances the traffic over a pair of evented, homegrown apps that we call the broxy (Braintree proxy). The broxy puts the requests into a redis queue, and dispatchers feed off the queue and process the requests through Rails (using rack). We can pause traffic by stopping the dispatchers. The broxy will continue putting request into redis, and since the dispatchers are stopped, the requests will queue and wait. Since the clients maintain a web connection with the Broxy, they will wait until the dispatchers start again and the request is handled. This is how we perform deploys with database migrations and infrastructure work without downtime. A few requests will take longer, but they will all get processed when the dispatchers start back up.
With the data center move, the broxy was the key piece in ensuring that we could pause traffic for the final cutover and not lose requests. Requests will take longer, but they will eventually process.
Another core component to our infrastructure is DRBD. We use DRBD to replicate our database servers.
The move, step by step
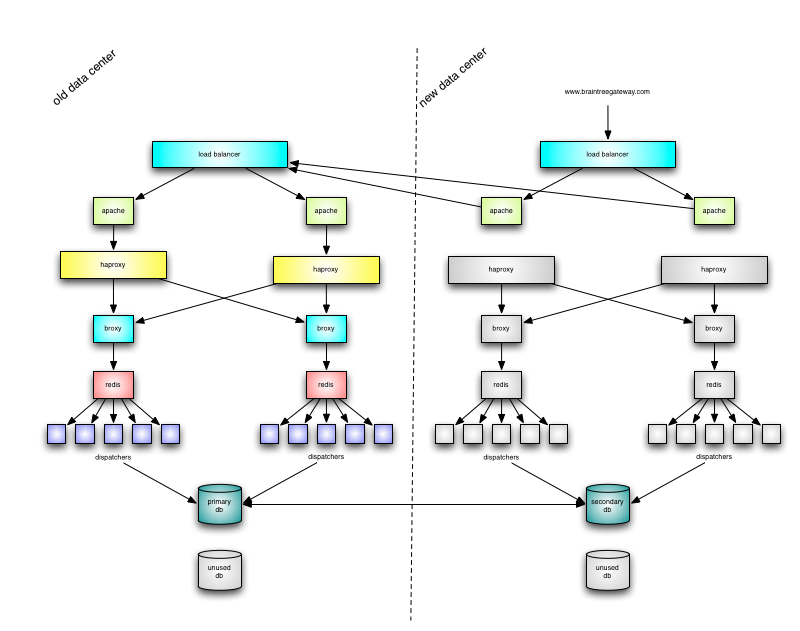
Step 1: Move DNS and change DRBD sync
The first step in our data center move was to switch to a BGP IP address. DNS propagation is slow, however, so we decided to proxy traffic for a day to make sure everyone switched to the new IP.
We set up an apache in the new data center and configured it to proxy all traffic to our existing data center. Then, we switched our DNS to this new IP and waitied for traffic to switch. We also wanted to make sure our merchants could connect to the new IP without problems.
While our DNS was propagating, we changed our DRBD configuration to sync between the two data centers. This kicked off a full resync which took some time to catch up.
Step 2: Switch to broxy in new data center
The next step was to set up a pair of broxies in the new data center with a pool of dispatchers in the old data center. This step put us into a state where we could pause traffic in the new data center.
Switching our apache from proxying to routing through the broxy was a simple reload and involved no downtime. broxy in new data center
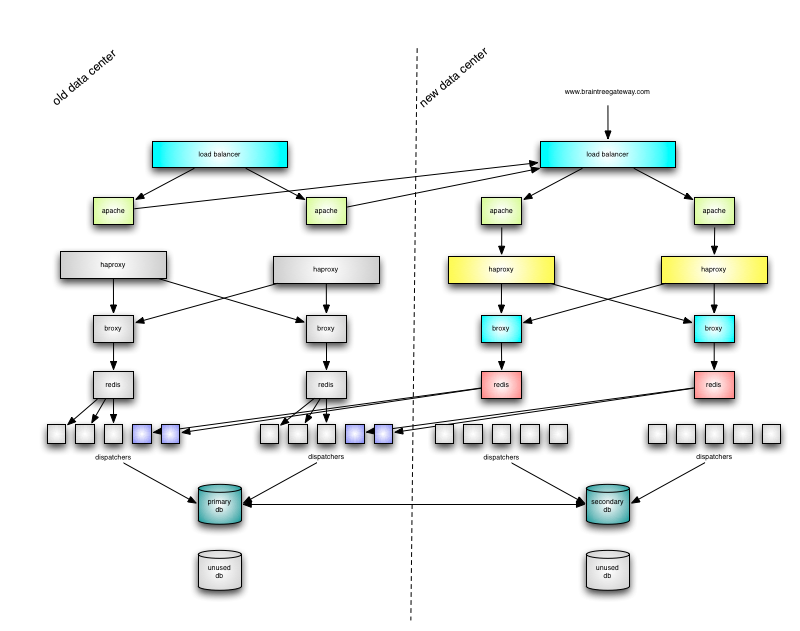
Step 3: Send all traffic through new data center
By this point, 99% of our traffic was flowing through the new data center. However, DNS propagation is slow and unreliable, and we still had a few merchants coming in over the old IP. To handle these requests, we set up a proxy in our old data center to proxy requests to our new data center. This ensures that all traffic is flowing through our new broxies.
Step 4: The cutover
With all traffic flowing through the broxies, we were able to do the final cutover:
- Stop dispatchers in old data center
- Switch DRBD primary to new data center
- Start dispatchers in new data center
The final cutover took a little less than a minute, requests queued, and then were fully processed in the new data center.
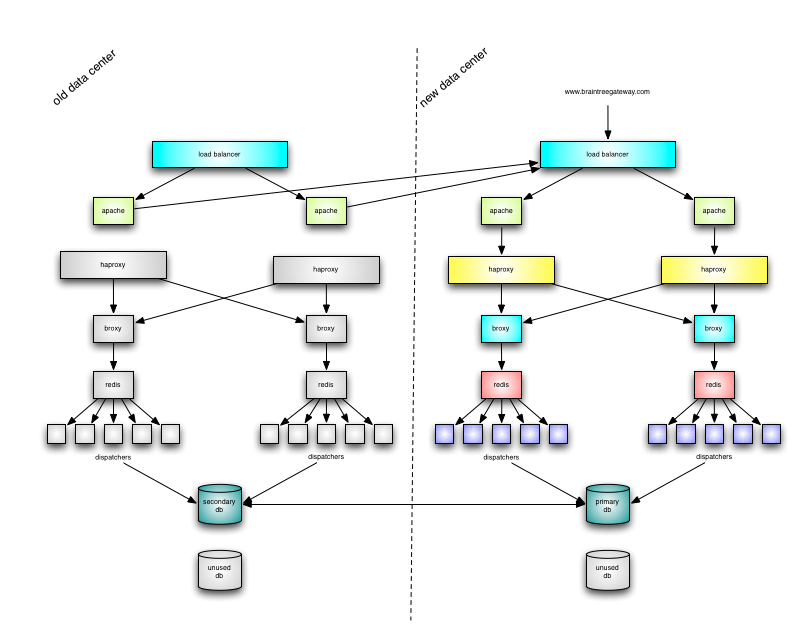
Step 5: Cleanup
Once we completed the final cutover, we reconfigured DRBD again to sync between the databases in the new data center. We also finished setting up a few non-critical services in the new data center, including an instance of sphinx for basic search and a mongodb replica set for logging data.
Next steps
Now that our traffic is fully migrated to the new data center, we can rebuild our existing data center with the new equipment. Then, we plan to connect the two data centers in a fully active-active configuration, with traffic flowing into both data centers concurrently (through the magic of BGP). This will allow us to survive even a complete data center failure with very little downtime. Furthermore, we will be able to unbalance an entire data center for future infrastructure work.